



1 GPT-SoVITS介绍
GPT-SoVITS是花儿不哭大佬研发的低成本AI音色克隆软件。目前只有TTS(文字转语音)功能,将来会更新变声功能
项目地址:https://github.com/RVC-Boss/GPT-SoVITS
TTS(Text-To-Speech)这是一种文字转语音的语音合成
GPT-SoVITS实现了:
- 由参考音频的情感、音色、语速控制合成音频的情感、音色、语速
- 跨语种文字转语音,比如参考音频是英文,可学习其音色、情感、语速将中文文本转成中文语音
2 GPT-SoVITS安装
macOS Sonoma 一键安装
下载安装
iCloud链接:https://www.icloud.com/iclouddrive/09ccZHBu_b_Aj4LKZgW0HxxrA#GPT-SoVITS
下载后并解压,找到install for mac.sh,终端执行bash+空格+拖拽install for mac.sh文件
注意事项
将安装包解压到macOS的移动硬盘,如果使用软件解决读取NTFS移动硬盘的方案会导致程序运行异常
解决方案:将macOS上的移动硬盘格式化成 APFS格式
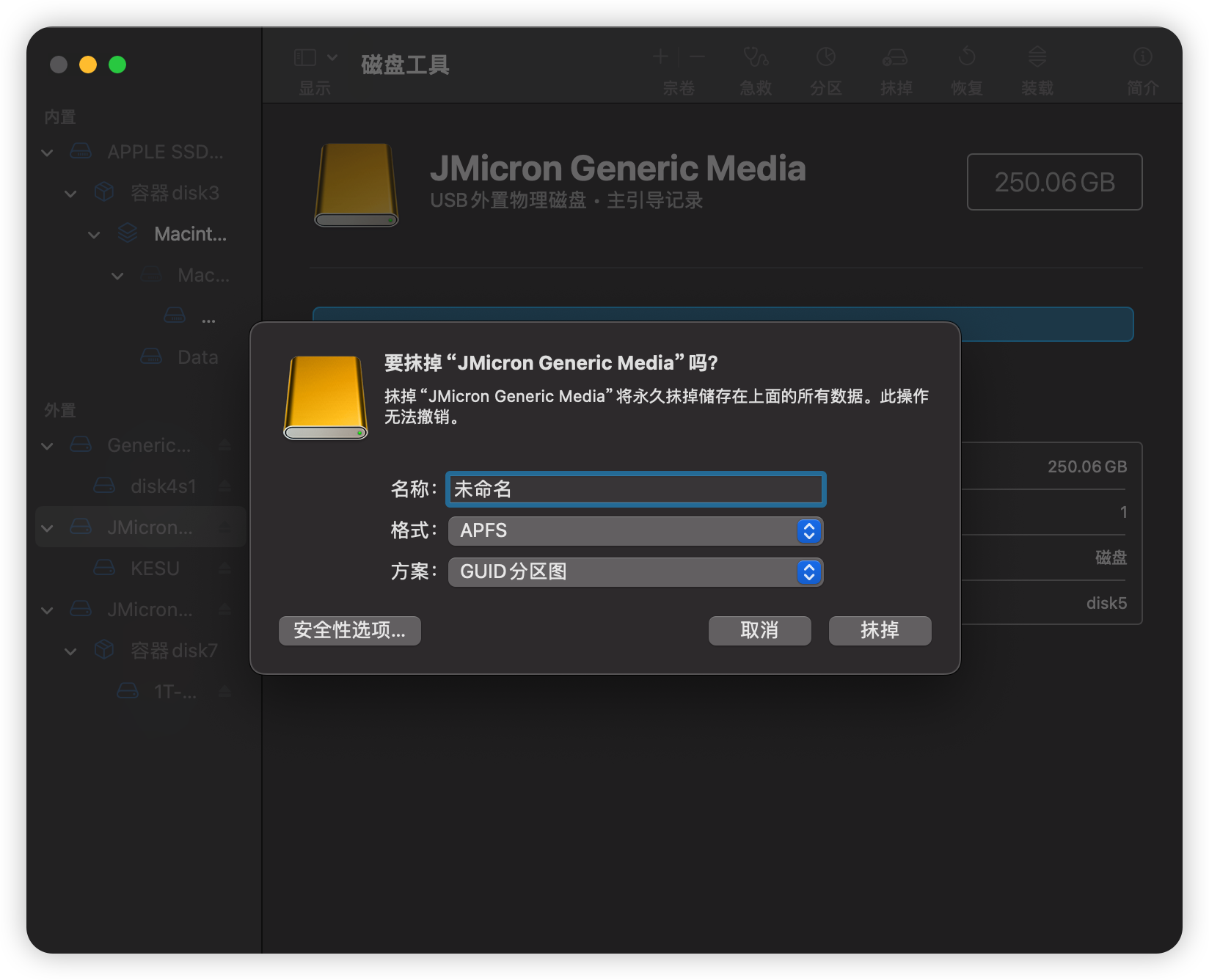
方法:找到磁盘工具 -> 选择要格式化的硬盘->选择该磁盘的最顶级->点击抹掉->按下图所示进行设置->点击抹掉(有数据记得提前备份)
3 GPT-SoVITS上手
3.1 声音样本处理
3.1.1 人声分离
使用自带的UVR5工具,执行HP2模型将人声和背景音去除,注意尽量选择bgm不太大的声音样本
执行完后, 将纯背景音音频文件删除,保留纯人声音频文件
3.1.2 去混响
将上一步保留的纯人声音频作为源,执行onnx_dereverb 模型,对处理完生成的两个文件保留带main命名的音频文件,删除带other的音频文件
同样的操作最后再使用 DeEcho-Aggressive模型去混响,保留最终去完混响的音频文件在后续步骤中使用
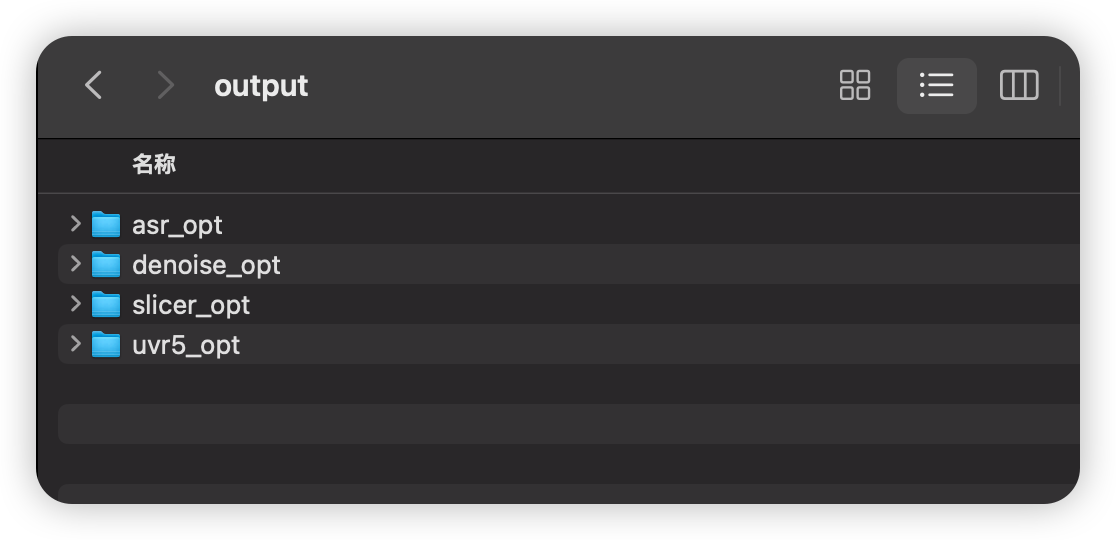
执行完上述步骤后,会在 output\uvr5_opt 目录下生成我们需要的声音样本文件
3.2 切割声音样本
选择上述处理好的音频源文件,将文件路径按如下图所示贴到左上角位置,点击开启语音切割
执行完上述步骤后,会在 output\slicer_opt 目录下生成我们需要的声音样本文件
3.3 降噪
将上述声音样本切割完生成的
slicer_opt音频文件路径贴到降噪音频文件输入文件夹处 ,并开启语音降噪
执行完上述步骤会在 output\denoise_opt 目录下生成降噪处理后的声音样本文件
3.4 声音样本语音转文字
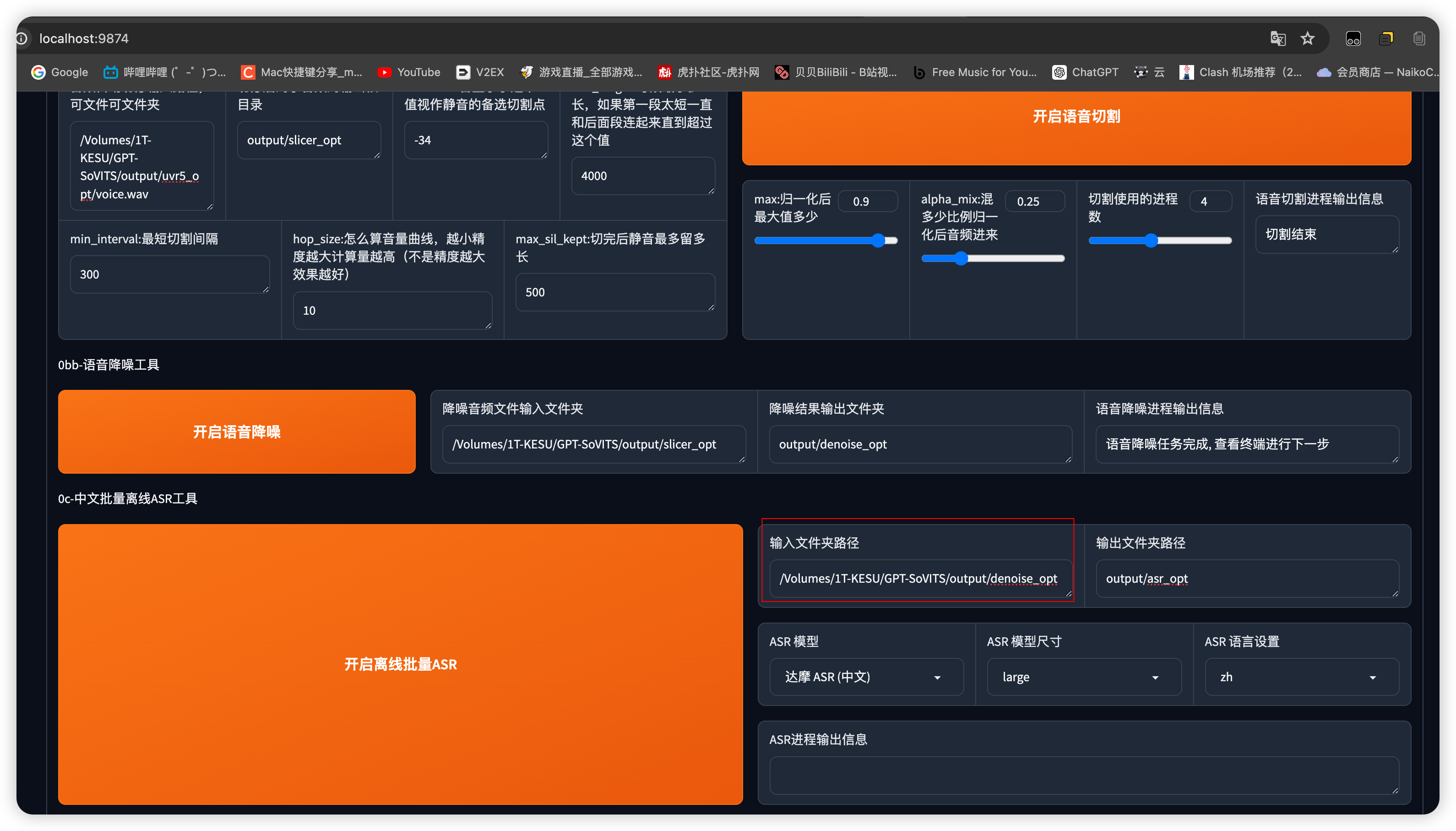
将上述声音样本切割完生成的
denoise_opt音频文件路径贴到如下图所框选处 ,并开启离线批量ASR
执行完上述步骤会在 output\asr_opt 目录下生成声音样本转文字的文本文件,如下图所示
3.5 文字校对
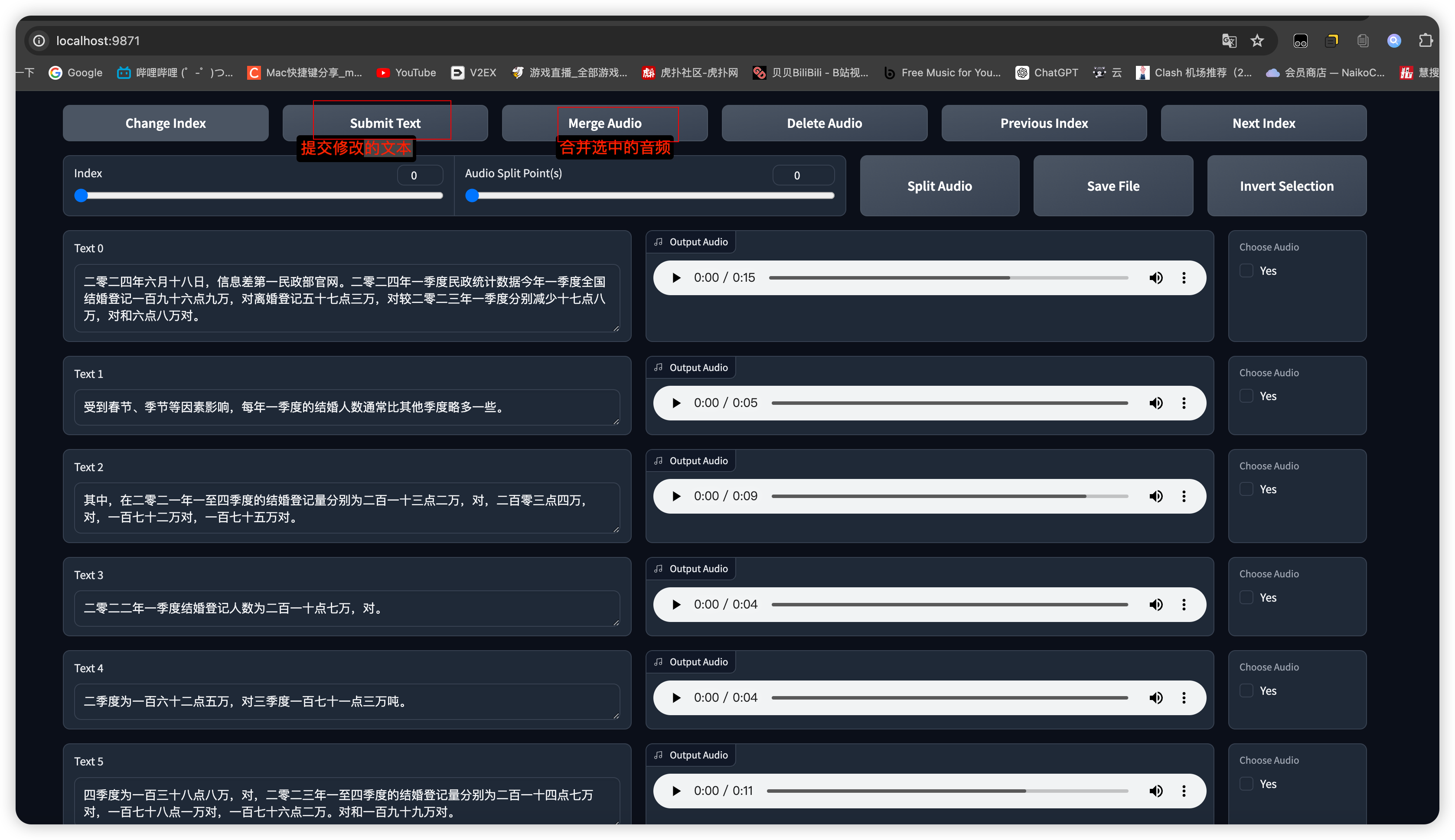
点击勾选打开文字校对UI,并填入上述
asr_opt文件下生成的 .list文件路径,会进入到新的页面对文字进行修改,每一页修改完都要点一下保存修改(Submit Text),如果没保存就翻页那么会重置文本,在完成退出前要点保存文件(Save File)
3.6 数据格式化
将伤处修改好的语音转文字 .list文件路径,和切割完并进行降噪处理的声音片段文件夹路径分别贴到对应的
问班标注文件、训练集音频文件目录如下图所示,并开启一键三连
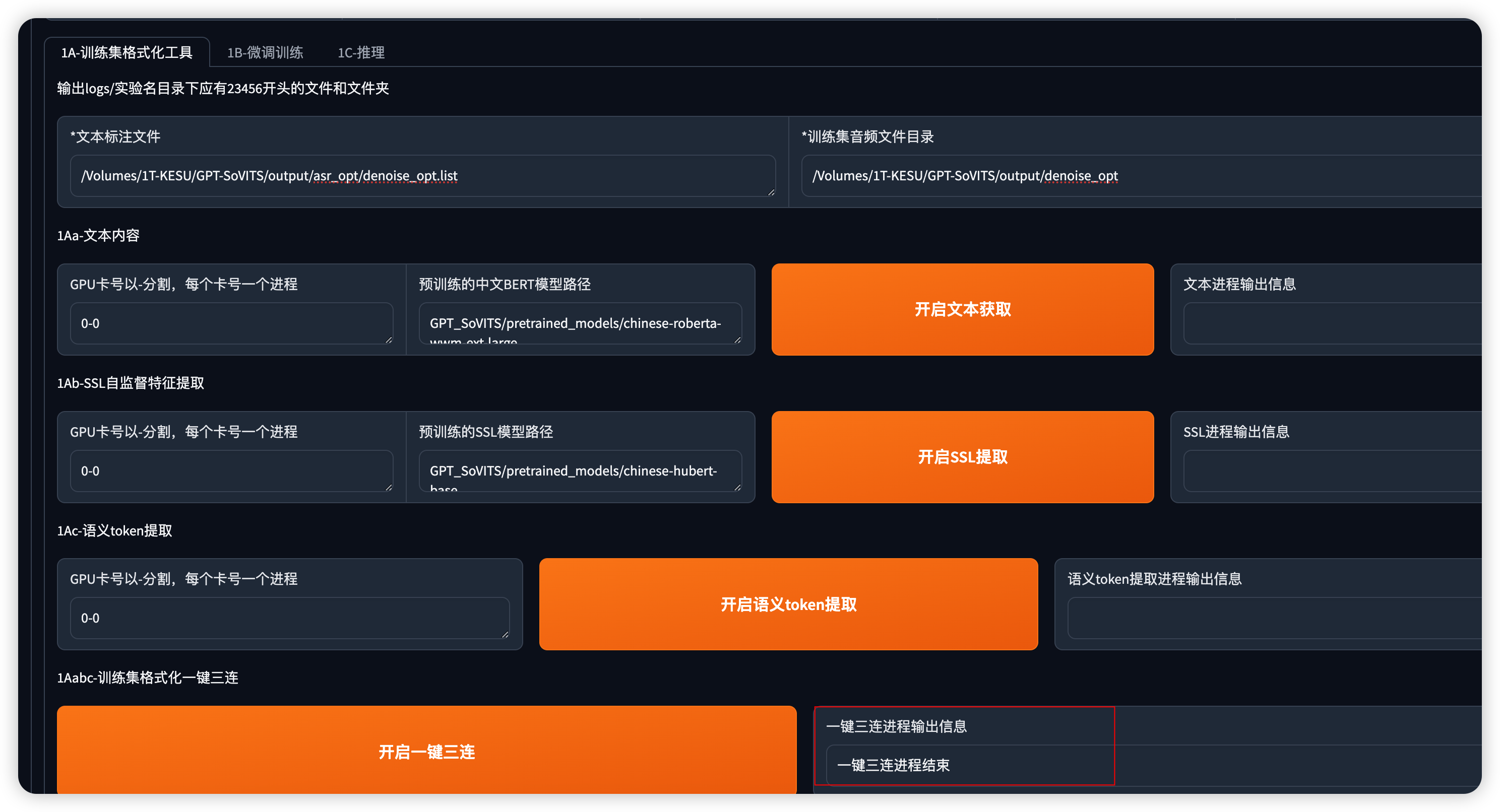
执行完会显示 一键三连已结束,为下一步语音样本克隆模型做准备
3.7 声音模型训练
为模型取一个英文名称,按如图所示开启SoVITS、GPT训练
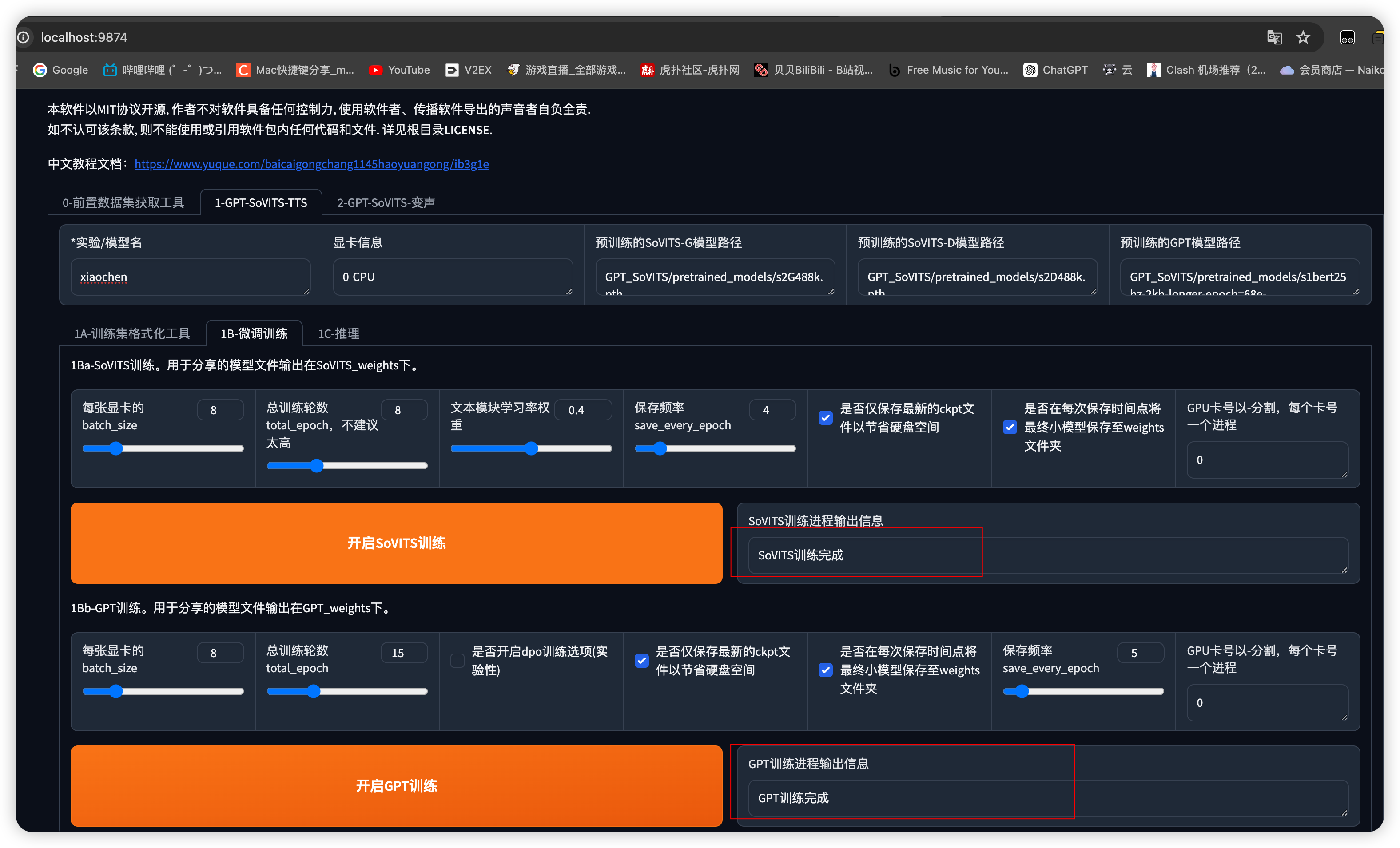
训练结束会提示训练完成
3.8 文字转语音推理
找到推理tab,刷新模型,可以开始文字转语音体验


评论区